Common warning signs before server outages
Everyone knows that server outages and server down time cost. It directly affects your business in a number of ways including:
- Loss of opportunities
- Damage to your brand
- Data loss
- Lost sales
- Lost trust
It’s essential to stay on top and ahead of any potential downtime.
Here are three areas where you need to be ahead of the curve:
Know your limits / server resources
Physical resource shortages
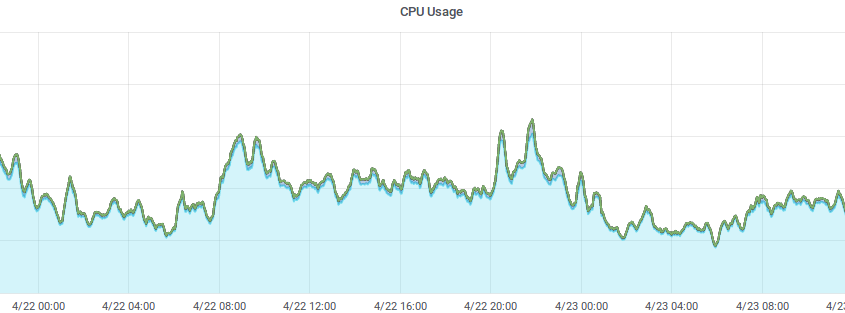
A common cause of downtime is from running out of server resources.
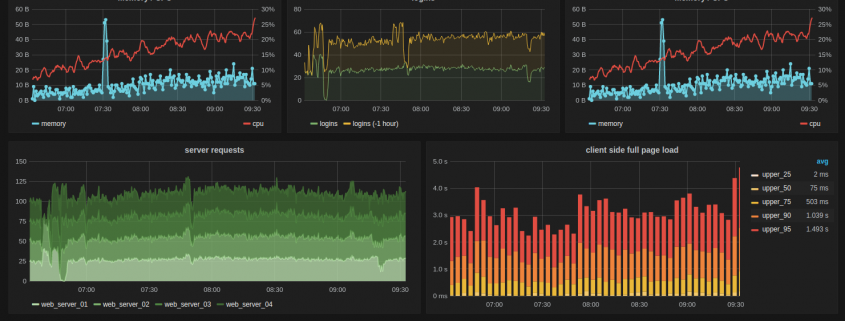
Whether it is RAM, CPU, disk space or other, when you run out, you risk data corruption, programs crashing and severe slowdowns to say the least. It is essential to perform regular server monitoring of your resources.
One of the most important; yet overlooked metrics, is disk space. Running out of disk space is one of the most preventable issues facing IT systems in our opinion.
When you run out of disk space, your system can no longer save files, losing data and leading to data corruption.
Often your website might still look like it is up and running and it’s only when a customer interacts with it, perhaps uploading new data or adding an item to a shopping basket, that you find it then fails to work.
We see this happen most frequently, when there is a “run-away log file” that keeps expanding until everything stops on the server!
CMS systems like Magento fall particularly prey to this as they often have unchecked application logs.
Internally, we record all server resource metrics every 10 seconds onto our MINDER stack and alerts will be raised well in advance of disk space running out. You don’t need to be this ‘advanced’ – you could simply have a script check current disk space hourly and email you if it is running out.
Configured resource shortages
Another common resource limit is a misconfigured server.
You could have a huge server with more CPU cores, RAM and storage than you could dream of using, but if your software isn’t configured to use it it won’t matter.
For example, if you were using PHP-FPM, and hadn’t configured it correctly, it would only have five processes running to process PHP. This means that in the case of a traffic spike, the first five requests would be served as normal but anything beyond that 5th request will be queued up until the first five had been served. This will of course needlessly slowing the site down for visitors.
Issues like this are often flagged up in server logs, letting you know when you hit these configured limits, so it is good to keep your eyes on them. These logs can also indicate that your site is getting busier and help you to grow your infrastructure in good time, along with your visitors.
You might be thinking, “why are there these arbitrary limits getting in my way? I don’t need these at all”.
Well, it is good to have these limits so that in the case of an unusual traffic spike, everything will run slowly but importantly it will work! If they are set too high, or not set at all, you might reach the aforementioned “physical limits” issue risking data corruption and crashing.
Did you know, by default NGINX only runs with one single threaded worker!
Providers
As a small business, it is normally impossible to do everything in house – and why would you want to, when you need to focus on your business?
So it is good to step back every once in a while and document your suppliers.
Even if you only own a simple website, suppliers could include:
- Domain registrar (OpenSRS, Domainbox, …)
- DNS providers (Route 53, DNS Made Easy, …)
- Server hosting (Rapidswitch, Linode, AWS EC2, …)
- Server maintenance (Dogsbody Technology, …)
- Website software updates (WordPress, Magento, …)
- Website plugin updates (Akismit, W3 Total Cache, …)
- Content Delivery Network (Cloudflare, Akamai, …)
- Third parties (Sagepay, Worldpay, …)
All of these providers need to keep their software and/or services up to date. Some will cause more impact on you than others.
Planned maintenance
Looking at server hosting, all servers need maintenance every now and again, perhaps to load in a recent security update or to migrate you away from ageing hardware.
The most important point here is to be aware of it.
All reputable providers will send notifications about upcoming maintenance windows and depending on the update they will let you reschedule the maintenance for a more convenient time – reducing the effect on your business.
It is also good to have someone (like us) on call in case it doesn’t go to plan. Maintenance work might start in the dead of night, but if no one realises it’s still broken at 09:00, heads might roll!
Unplanned maintenance
Not all downtime can is planned. Even the giants, Facebook and Amazon have unplanned outages now and again.
This makes it critical to know where to go if your provider is having issues. Most providers have support systems where you can reach their technical team. Our customers can call us up at a moments notice.
Another good first point of call is a provider’s status page, here you can see any current (as well as past or future) maintenance or issues that are occurring. For example if you use Linode you can see issues on their status page here.
Earlier this year, we developed Status Pile a webapp, which combines provider status information into one place, making it easier for you to see issues at a glance.
Uptime monitoring
This isn’t really a warning sign, but it’s impossible to foresee everything. The above areas are great places to start, but they can’t cover you for the unexpected.
That’s where uptime monitoring comes in. Regardless of the cause, you need to know when your site goes down and you need to know fast.
We recommend monitoring your website at least minutely with a provider like Pingdom or AppBeat.
Proper configuration
Just setting up uptime monitoring is one thing, but it is imperative to configure it properly. You can tell someone to “watch the turkey in the oven” and so they watch the turkey burn!
I’ve seen checks which make sure a site returns a webpage, but if that page says, “error connecting to database” it doesn’t matter!
Good website monitoring checks the page returned includes the correct status code and site content. Perhaps your website connects to your docker application but only for specific actions then you should test specifically as well.
Are you checking your entire website stack?

Who is responsible?
A key part of uptime monitoring – and a number of other items I have mentioned – is that it alerts the right people and that they action those alerts.
If your uptime alerts flag an outage and they are sent to an accounts team it’s unlikely they’ll be able to take action. Equally if an alert comes in late in the evening when no one is around your site might be down until 0900 the next morning.
This is where our maintenance service comes in. We have a support team on call 24/7, ready to jump on any issues.
Phew that was a lot, we handle all of this and more. Contact us and see how we can give you peace of mind.
Feature image by Andrew Klimin licensed CC BY 2.0.